
Edge AI and On-Device Models: The Reality Check
October 2025? It was another one of those months where the AI hype machine went into overdrive

Let me tell you something that might surprise you. I’ve seen enough “revolutionary” technology announcements to fill a graveyard. And October 2025? It was another one of those months where the AI hype machine went into overdrive. But here’s the thing: this time, buried under all the marketing noise, there’s actually something worth paying attention to.
I remember when everyone was losing their minds over cloud computing. “Everything will run in the cloud!” they said. “Local processing is dead!” they proclaimed. Now, in 2025, we’re watching the pendulum swing back. Not because the cloud failed, but because physics, economics, and reality have a way of catching up with hype.
IBM released its Granite 4.0 Nano models on October 29th. Google’s Coral NPU is delivering 512 GOPS at milliwatt power consumption. Meta shipped PyTorch ExecuTorch 1.0 for production edge deployment. Some researchers at Osaka University claim they’ve built a system called MicroAdapt that processes data 100,000 times faster than conventional deep learning. Industry analysts predict that 43% of PCs will have Neural Processing Units (NPUs) by the end of 2025.
Sounds impressive, right? However, let me be perfectly honest with you: most articles covering this topic are simply regurgitating press releases. What I want to do here is cut through the BS and tell you what’s actually happening, why it matters, and more importantly, what it means for anyone building real systems in the real world.
The Cloud AI Party Is Over (Sort Of)
Here’s what nobody wants to admit out loud: sending every piece of data to the cloud for AI processing is expensive, slow, and increasingly problematic from a privacy standpoint. I’ve worked on enough data architectures to know that network latency isn’t just a technical inconvenience; it’s a fundamental constraint that no amount of optimization can eliminate.

The difference is brutal. Cloud AI provides a latency of 100 to 400 milliseconds. Edge AI? We’re talking 1 to 10 milliseconds. And that’s not even accounting for what happens when your network connection drops, which, believe me, happens more often than cloud providers want you to think about.
IBM’s Granite 4.0 Nano: Small Models That Don’t Suck
On October 29, 2025, IBM released a product called Granite 4.0 Nano. Two models: 350 million parameters and 1 billion parameters. Now, before you yawn and think “oh great, another language model,” let me tell you why this actually matters.
First, they released it under the Apache 2.0 license. That means you can actually use it commercially without some lawyer breathing down your neck. I’ve seen too many “open” models that come with licenses that make them useless for anything beyond academic research.
Second, and this is the kicker: these models are small enough to run on smartphones and IoT devices while consuming milliwatt-level power. Not watts. Milliwatts. That’s the difference between a device that needs charging every few hours and one that can run for days or weeks.
I can clearly say that after working with various language models over the past few years, the problem has never been whether we can build massive models. Of course, we can. The problem is whether we can build models that normal humans can actually deploy and run without needing a data center.
Here’s what the power consumption looks like across different model sizes:
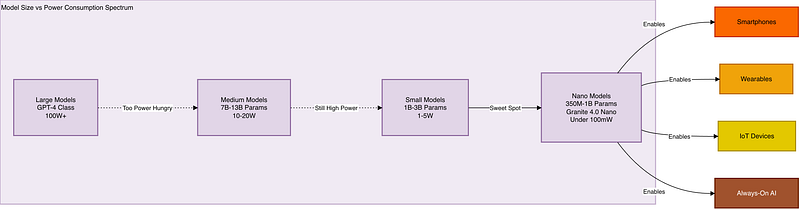
The sweet spot is those Nano models on the right side. That’s where you can actually build products that people can use without draining their battery in an hour.
Google Coral NPU and the Hardware Reality
Now let’s talk about hardware. Because here’s something most software engineers don’t want to think about: software doesn’t run on magic. It runs on silicon. And the silicon matters.
Google’s Coral NPU (Neural Processing Unit) delivers 512 GOPS (giga-operations per second) at milliwatt power levels. What does that actually mean? It means you can run AI inference continuously, always on, in a wearable device without killing the battery.
I can tell you that most software engineers have no idea how their code actually executes on hardware. They write Python, throw it at some cloud API, and call it a day. However, when building edge AI systems, it is essential to understand the hardware constraints.
The Coral NPU isn’t trying to be everything to everyone. It’s specialized for inference, not training. It’s designed for always-on, low-power scenarios. And that’s exactly the right approach. Many companies attempt to develop general-purpose solutions that often fail to deliver on their promises.
MicroAdapt: Self-Evolving Edge AI (or Just More Hype?)
On October 30th, researchers at Osaka University announced something called MicroAdapt. They claim it processes data 100,000 times faster than conventional deep learning with 60% higher accuracy. That’s the kind of claim that immediately sets off my BS detector.
Let me be clear: I’m not sure if MicroAdapt is revolutionary or just another academic paper that will never be deployed in the real world. I’ve seen too many “breakthrough” announcements that turned out to be carefully benchmarked on specific datasets under specific conditions that don’t generalize.
But here’s what’s interesting about the concept, regardless of whether this specific implementation delivers: the idea of self-evolving edge AI that adapts locally without constant cloud communication. That’s actually a sensible architectural pattern if you can pull it off.
The challenge with edge AI isn’t just running inference locally; it’s also about managing the data. It’s keeping the models updated and relevant. Traditional approaches require you to either:
Periodically download new models from the cloud (expensive in terms of bandwidth and time)
Send data back to the cloud for retraining (defeats the privacy benefits of edge AI)
Run with static models that become outdated (lose accuracy over time)
A system that can adapt locally, learning from new data without compromising privacy or requiring constant connectivity? That would actually be useful. But I’ll believe it when I see it deployed at scale in production systems, not just in a research paper.
Meta’s PyTorch ExecuTorch 1.0: The Framework That Actually Matters
On October 22nd, Meta released PyTorch ExecuTorch 1.0. This one actually matters, and here’s why: frameworks are what make or break a technology’s real-world adoption.
You can have the most brilliant hardware and the most optimized models, but if developers can’t actually use them without spending six months figuring out toolchains and build systems, nobody will adopt them. I can tell you that developer experience is often more important than raw performance.
ExecuTorch is Meta’s production-ready framework for deploying PyTorch models to edge devices. The fact that it’s reached 1.0 status means Meta is actually using it in production systems that serve billions of users. That’s not academic research. That’s battle-tested infrastructure.
Here’s the deployment decision tree you should actually be thinking about:
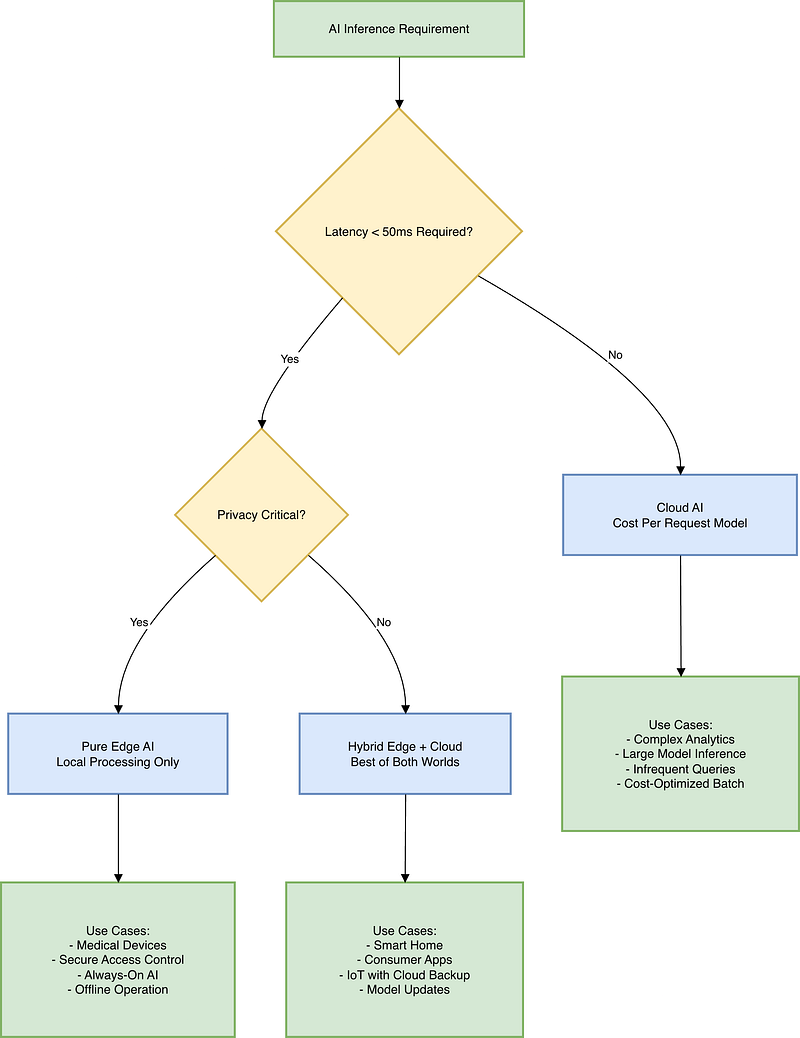
Most real-world systems ultimately fall into this hybrid category. Pure edge AI for latency-critical and privacy-critical operations, with cloud backup for model updates, complex analytics, and scenarios where you have time and bandwidth to spare.
The NPU Revolution: 43% of PCs by the End of 2025
Industry analysts predict that 43% of PCs will feature NPUs by the end of 2025. That’s a massive shift. But here’s what they’re not telling you: having an NPU in your device doesn’t automatically make everything better.
I switched from macOS to Linux after 20 years, and what I learned is… Hardware capabilities are meaningless if the software ecosystem isn’t in place to utilize them. Apple has been incorporating neural engines into its chips since the A11 in 2017. But how many applications actually take advantage of them effectively? A fraction.
The challenge isn’t just manufacturing chips with NPUs; it’s also about integrating them effectively. The challenge is:
Creating frameworks that make them easy to use (that’s where ExecuTorch comes in)
Providing models that are actually optimized for edge deployment (that’s the Granite Nano approach)
Building tools and workflows that let developers deploy and update edge models without losing their minds
Establishing clear patterns for when to use edge vs cloud vs hybrid architectures
And the worst part is that most companies are simply slapping “AI-powered” on their product descriptions without actually thinking through these architectural decisions. It’s marketing-driven development, and it’s terrible.
What This Actually Means for Real Systems
Let me bring this back to reality. If you’re building systems in 2025, here’s what you should actually be thinking about:
1. Start with your constraints, not your ambitions
Don’t start by saying “we want AI in our product.” Start by asking: What are our latency requirements? What are our privacy requirements? What’s our power budget? What’s our connectivity situation? Then decide if edge AI makes sense.
2. Small models are getting good enough for most use cases
You don’t need GPT-4-level capabilities for 90% of real-world AI tasks. A well-trained 1B parameter model running locally can often deliver a better user experience than a 100B parameter model that requires a round trip to the cloud. Trust me on this.
3. The hybrid architecture is your friend
Stop thinking in terms of “edge or cloud.” Think “edge and cloud.” Use edge AI for real-time, latency-sensitive operations. Use the cloud for model training, complex analytics, and scenarios where you have time to wait for results. Sync intelligently between them.
4. Power consumption is a feature, not just a specification
When IBM says its Granite Nano models run at milliwatt power levels, that’s not just a technical detail. That’s the difference between a product that users can actually use all day and one that they’ll disable to save battery. I’ve seen too many technically impressive AI features that users turn off because they drain the system too quickly.
5. Frameworks matter more than you think
The reason to pay attention to PyTorch ExecuTorch isn’t because it’s technically superior to every alternative. It’s because it has Meta’s production deployment experience behind it and a large developer community. In 2025, you don’t want to be the person debugging obscure edge AI deployment issues with a framework that has three users and no documentation.
About Edge AI
Here’s something nobody wants to talk about: most edge AI deployments will fail not because of technical limitations, but because teams don’t understand their actual requirements.
I’ve been in this industry long enough to see a pattern: new technology emerges, everyone gets excited, companies rush to adopt it, and then 80% of implementations are abandoned or scaled back because they didn’t actually solve a real problem.
Edge AI is incredibly powerful for specific use cases:
Real-time video processing where latency matters (security cameras, autonomous vehicles)
Privacy-critical applications where data cannot leave the device (medical devices, secure access control)
Always-on scenarios where battery life is critical (wearables, IoT sensors)
Offline operation where connectivity is unreliable (industrial equipment, remote monitoring)
But if your use case doesn’t have those constraints? The cloud might still be the better answer. Don’t let the hype tell you otherwise.
Final Thoughts: Experience Over Articles
I know this is not easy. Edge AI is complex. The hardware landscape is fragmented. The software tooling is still maturing. The models are getting better, but they’re not magic.
What I have seen over 20+ years is that the technology that wins isn’t always the most technically impressive. It’s the technology that solves real problems with a reasonable trade-off between capability and complexity.
IBM’s Granite Nano models, Google’s Coral NPU, and Meta’s ExecuTorch framework are tools. Good tools, potentially. But tools nonetheless. The question isn’t “should I use edge AI?” The question is, “Do I have a problem that edge AI solves better than the alternatives?”
And here’s the kicker: you won’t know the answer by reading articles (including this one). You’ll know by building something, measuring it, and comparing it to alternatives. That’s how engineering actually works.
The edge AI revolution is real. But it’s not going to look like the breathless press releases suggest. It’s going to be messy, incremental, and constrained by real-world physics and economics. Just like every other technology revolution I’ve lived through.
But for the first time in a while, the fundamentals actually make sense. Low-power AI chips that can run meaningful models. Frameworks that make deployment practical. Models are small enough to be useful but capable enough to solve real problems. That’s not hype. That’s progress.
Now go build something. And when it doesn’t work the first time (and it won’t), iterate. That’s the actual process.